Using SLZ for network backups
Backups over the network are always a problem :
if the disk is sent uncompressed, it saturates the network
if the disk is sent compressed, it saturates the CPU
if cheaper, non-standard compression algorithms are used, the archives need to be decompressed and recompressed on the backup server, reintroducing the previous point on the backup server.
While running some performance tests on SLZ, I realized that it could represent an interesting tradeoff for this specific use case. Thus I ran some tests on my PC, which is connected over gigabit to the local network where the backup server is.
I've conducted a few series of tests :
full rootfs transfer over the network uncompressed
full rootfs transfer over the network via gzip
full rootfs transfer over the network via SLZ
The test platform has the following characteristics :
CPU: core i7 6700K at 4.4 GHz (4 cores)
RAM: 16 GB DDR4-2400
SSD: OCZ-VERTEX3 240 GB / SATA3
LAN: intel i219 (e1000e)
OS: Linux 4.4 (slackware64 14.2)
gzip: version 1.8
libslz: 1.1.0-9-gd7444f
To avoid any throttling on the network server (10.8.1.2 here during the test), it was only running netcat to /dev/null :
$ nc -lp4000 >/dev/null
I wanted to measure I/O bandwidth and network bandwidth in parallel but usually that's not easy due to the bursty nature of I/O traffic caused by large readahead which often results in impulses on traffic graphs. In order to simplify this, I decided to stream the disk using netcat over the loopback. That makes it much more convenient since we can compare megabits with megabits, both entering and leaving the compression utility. At this moderate network rate limited to 1 Gbps, netcat uses little CPU and was running on a dedicated core (cpu#0) so it doesn't affect the measures at all. Thus the disk was streamed this way (the rootfs partition is 64.4 GB) :
# taskset -c 0 nc -q0 -lp4000 </dev/sda5
The test then consists in inserting the compression utility between the two sockets, running on its own CPU, like this :
$ time taskset -c 1 command </dev/tcp/127.0.0.1/4000 >/dev/tcp/10.8.1.2/4000
The commands involved were the following :
cat for uncompressed transfers
gzip -nc1 for gzip-compressed transfers (fastest mode)
libslz's zenc command line utility for slz-compressed transfers
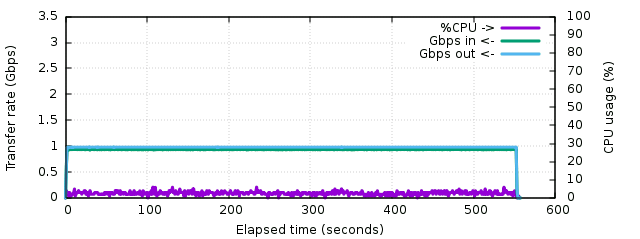
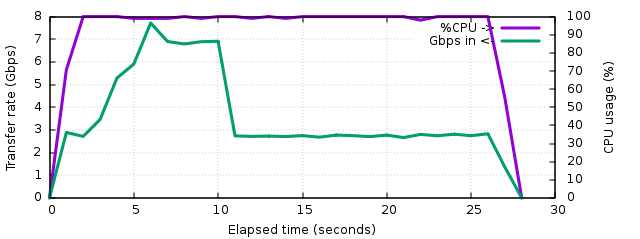
The first result using cat shows what is not a surprize, the network is saturated at 1 Gbps during all the transfer, so the total transfer time is the partition size divided by 1 Gbps, or 552 seconds exactly. The CPU usage remains around 2.5% :
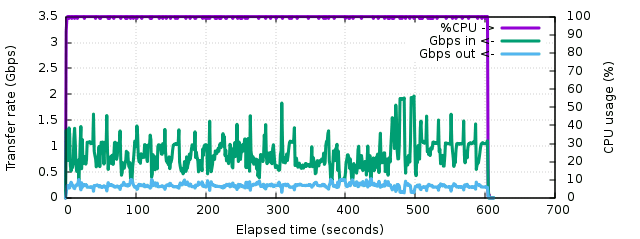
The second result using gzip provides an interesting result. First, as one could expect, the CPU is saturated at 100% during all the transfer. As a result, it's slightly slower than the uncompressed case, but not that much slower. The total transfer time climbed to 603 seconds, or less than 10% more. This means that with a network only 10% slower, both could match. The network traffic oscillates between 100 and 400 Mbps, more often around 220. So gzip can make a good use of this CPU for network bandwidths from 200 to 900 Mbps approximately. At least one important point to keep in mind is that for 10% longer transfer time, the backup server receives a compressed archive that can be stored as-is. The resulting archive is 16.98 GB, that's a compression ratio of 3.8, which is pretty good for a whole disk containing applications and many git repositories.
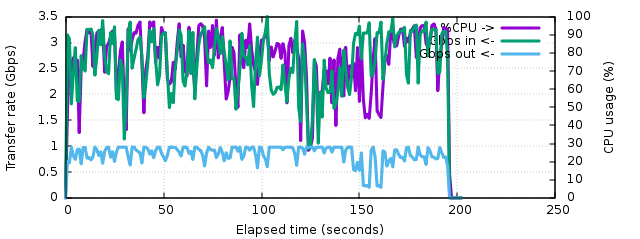
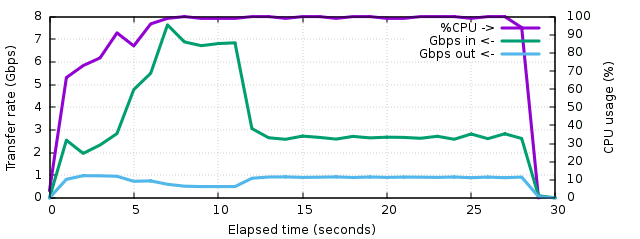
The third test using zenc actually demonstrates the benefits of inexpensive compression. The network interface is often saturated to 1 Gbps and the input traffic oscillates between 2 and 3.5 Gbps. The total transfer time is now of 195 seconds, 3 times less than with gzip. But the most interesting part is that the CPU has never gone beyond 72% usage, even when the network was not saturated. In parallel we clearly observe some regular peaks to the same limits on the input traffic. In fact, and that was the surprize, we've reached the limits of the SSD! This one saturates at 387 MB/s (slightly more than 3 Gbps) and most often doesn't go beyond 250 MB/s (it's been used a lot and might be a bit fragmented). The CPU measurements in parallel showed a permanent 48% to 85% I/O wait. The output file is 19.8 GB so that's a compression ratio of 3.25, which is still pretty good but a bit less interesting than gzip's.
A plain read of this disk with vmstat running in parallel shows the same traffic pattern as this last one so now it's pretty clear we're capping on I/O.
In order to see how far we could go, I decided to put some similar contents in RAM since there's enough on this machine to run reasonably relevant tests. So I created a tar archive into /tmp in which I copied 12 GB of files :
an Ubuntu rootfs image I have here (1.7 GB), it will replace the system's executables ;
a copy of the Silesia corpus test files (211 MB) ; these ones are used to test compression tools and contain various applications and files ;
my system's logs (5 GB, I should do some cleanup) ; these are expected to be highly compressible ;
Linux kernel sources for all the LTS kernels (3.2, 3.4, 3.10, 3.16, 3.18, 4.1, 4.4, 4.9), that's 5.5 GB of sources
The resulting 12 GB file is then read once so that it populates the cache, and can later be read without any disk access, using netcat again :
# taskset -c 0 nc -q0 -lp4000 </tmp/big.tar
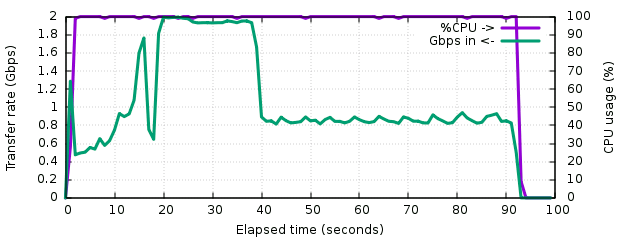
Now the gzip test shows a very regular traffic, and a few parts can even be distinguished during the transfer :
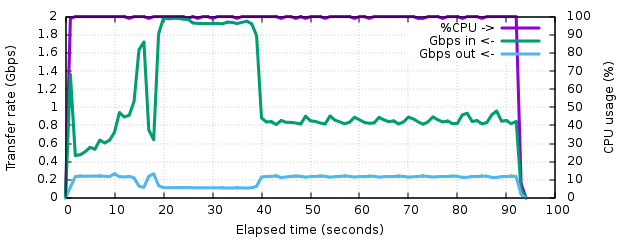
The first 15 seconds, til the first peak, correspond to the rootfs image. It's not 100% full, which explains the sudden peak of higher compression ratio near the end. Then the hole of less compressible traffic corresponds to the Silesia corpus. Then the large highly-compressible part are the logs, and the remaining flat part corresponds to kernel sources. Logs are compressed with a ratio approaching 16:1 which is common for such type of payload. At this point gzip reaches 2 Gbps of input payload on the logs and around 900 Mbps on source code. The executables are variable, between 500 and 900 Mbps. Overall the outgoing traffic remains stable around 220 Mbps. The total transfer time was 92 seconds.
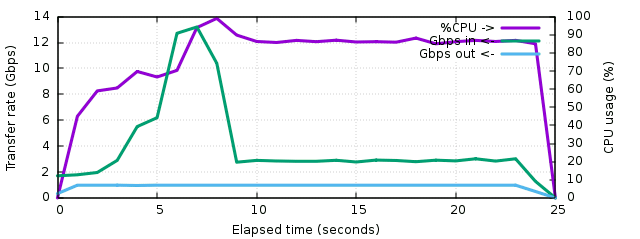
The SLZ test managed to almost saturate the network most of the time, and was still CPU bound for most of the transfer. Only the first 5 seconds managed to be network-bound. The network traffic was lower during log transfers (6.5-7.5 Gbps in, 500 Mbps out), but the rest of the time the network was stable between 900 and 920 Mbps, with about 2.8 Gbps of input traffic on the kernel sources. The total transfer time was 28 seconds.
Since the CPU was constantly saturated, it sounds appealing to check what can be improved. Gzip compression involves the computation of a CRC32 over the input stream. This CRC is very expensive to compute. It never was optimized in SLZ since it was initially designed for web traffic where deflate is almost always supported and doesn't require such a CRC. By asking zenc to use the deflate format instead of the gzip format, it is possible to see what could be gained by improving the CRC computation :
The CPU is not saturated anymore (almost always 90%) and the transfer time decreased to 25 seconds, or 10% less than in the previous test. The network is constantly saturated now. It is interesting to see that during the log transfer, the input traffic almost doubled from 7.5 Gbps to 13 Gbps, which is what managed to make a better use of the network bandwidth. This means that during log transfers, the CRC was responsible for almost 50% CPU usage. During the rest of the transfers, it's more around 10% of the CPU usage. Thus it seems likely that optimizing the CRC algorithm a bit (cutting its cost in half) would at least ensure that we maintain a flat gigabit during all the source compression. For slower machines which cannot saturate their gigabit link, it can result in a bandwidth increase so it's worth investigating.
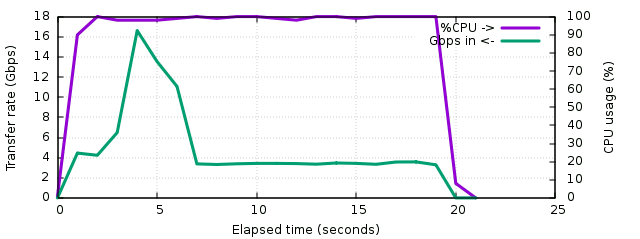
For reference, in order to see how far we can go when the output is not limited to 1 Gbps, a series of extra tests were run with the output sent to /dev/null. This allows to see what could be expected from the various compressors over 10 Gbps links, or just locally :
Gzip :
SLZ :
SLZ in deflate mode :
It's nice to see that SLZ without CRC32 is capable of compressing logs at 16 Gbps (2 GB of logs compressed in one second). It's 5 times faster than gzip on average and up to 8 times at peak performance. This can be convenient for local log processing, coupled with a fast decompressor. Also when the output is not saturated, sources are compressed at about 3.4 Gbps (420 MB/s). It definitely means that more work has to be done on the CRC32 algorithm in order to get the gzip-compatible stream as close as possible to this value. Some highly optimized versions exist using the PCLMULQDQ instruction on x86_64 machines, this will have to be studied in future versions. But in the mean time even without these optimizations, it shows that eventhough it was not initially designed for this purpose, slz is the fastest way to compress backups over gigabit links.
Back to libslz's home page
Created 2017-05-03, last updated 2017-05-03 - Willy Tarreau